The muted Seven – 7 things you should consider re confidential compute
by Bryan Ji – July 4, 2024
This piece walks you through the things you should understand and consider regarding confidential compute in blockchain. Privacy has always been a critical area to resolve and yet we can’t claim a clear win (see our previous article on addressing some of the long-lasting problems). The technical problem is real. However, the industry is making it even more difficult by oftentimes lumping together different solutions. This article attempts to break down the differentiating attributes of the widely used primitives ZKP, MPC and FHE for confidential computing. We also expand into how said cryptographic primitives are implemented on the system and dapp levels. By clearing up misconceptions, a more straightforward path to solutions could open up.
Source: Greenfield
#1 – #3: Exploring differences and connections between cryptographic primitives
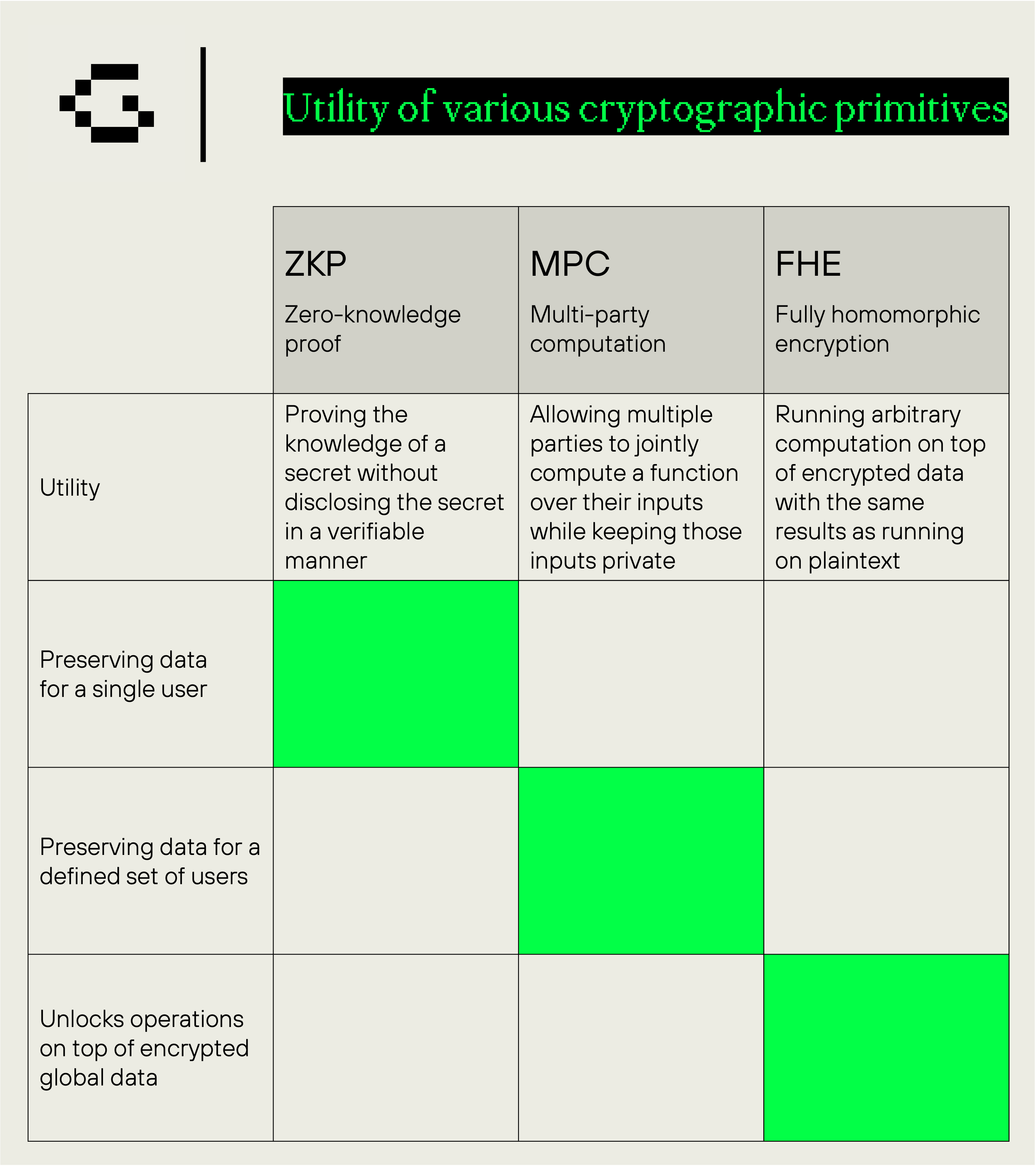
1_Cryptographic primitives provide different privacy utility.
In this context, utility refers to the extent to which a broad user base can simultaneously enjoy privacy. The greater the number of users who can share privacy at the same time, the higher the system’s utility. This concept is crucial because it highlights one of the core distinctions between different underlying cryptographic primitives such as Zero-knowledge proof (ZKP), Fully homomorphic encryption (FHE) and Multi-party computation (MPC):
_ZKP: prove the knowledge of a secret without disclosing the secret in a verifiable manner
_FHE: enable arbitrary computation on top of encrypted data; having the same result as running on plaintext
_MPC: allow multiple parties to jointly compute a function over their inputs while keeping those inputs private.
ZKP and MPC focus on preserving privacy for a single user or a defined set of users within the MPC environment. This approach restricts the number of participants who can share private information. In contrast, FHE enables operation on top of encrypted global data, and moreover, opens the access of the permissionless innovation with this data (which is in encrypted form) and thus offers broader flexibility and application
2_Cryptographic primitives have different trust assumptions.
Trust assumptions underpin how things could possibly go wrong so that users can be mindful with how much risk they would tolerate with the system. To break down a ZK (ZKSnark specifically) system, a fake zero-knowledge proof has to be forged. One way is to dictate the set-up phase, which happens when a program is deployed. The way to make the setup phase as trust-minimized as possible is to have as many participants as possible. Most systems today use a universal set-up, meaning the process doesn’t need to happen for every program to deploy and only happens when genesis.
The trust assumption of MPC is akin to that of the threshold FHE scheme. Both distribute the ‘decryption power’ to multiple parties and thus make sure no single person has access to screw up the system. In threshold cryptography, there is a threshold committee controlling the keyshares, collectively decrypting by combining keyshares when passing the threshold. In MPC, the most used trust scheme is honest majority or 2 ⁄ 3 honest majority, meaning either over half or over 2/3 of the participants act honestly.
3_Cryptographic primitives are composable/programmable.
In many cases, there is no one-size-fits-all solution, and the above-mentioned technologies are often bundled together for easy use. For example, one open research area that an FHE system is exploring is to find a practical way to verify the integrity of the computation (i.e. check if the computation is done correctly). There are a few possible ways to explore – run FHE in TEE (Trusted Execution Environment), run FHE in ZK, wrap FHE computation in an optimistic proof, or via economic consensus, or run redundant computation. In addition, as mentioned above, MPC is run in decrypting the output of FHE computation. The problem with MPC is that it is subject to collusiveness, see predecessor‘s case – multichain (TL;DR: all key shares are held by one person). When it happens, it is subject to a single point of failure and users’ funds are held in custody. Emerging solutions like 2pc-mpc by dwallet labs may provide a feasible solution but user liveness is an assumption to make it practical. Alternatively, we could try to explore running MPC in TEE, plus some economic flavor. Besides, a certain ZK proof called range proof is used often in other systems to prevent cases like overspend, such as in Arcium’s case.
The list goes on, ZKPs can be more efficient to run if we delegate the generation process to a powerful server, and the potential privacy problem can be mitigated by running the computation over a few machines via collaborative ZKP so that no single machine gets access to the whole piece of the secret.
Another interesting area to explore is programmability i.e. witness encryption, which allows statements to be encrypted/decrypted under programs instead of keys. It unlocks exciting applications such as encrypted orders for Cowswap by Fairblocks where intents can be specified as decryption criteria.
#4 – #5: Implementing cryptographic primitives
4_When implementing, privacy-oriented environments don’t share the same privacy settings.
One common misconception is that privacy settings (i.e., what part of the ‘workflow’ is actually private) should be identical while using a privacy-preserved blockchain. Before explaining why this is not the case, let’s address a few notions embedded in a private distributed system:
We have
_private input/output;
_private/public function;
_private/public address.
We can further group them into two baskets:
a_Confidentiality pertains to the input/function, describing whether the value or flow of the transaction is concealed.
b_Anonymity relates to the private/public address, indicating whether the identity that initiated the transaction is hidden.
Private input represents the hidden value that the user instructed the smart contract to execute on, e.g. how much USDC to swap to another token. Private output represents the updated state, which is also hidden but verifiable. Private input/output are the basic confidentiality features that every privacy-preserving blockchain provides. Atop is the function (i.e. smart contract) that the input is calling. Almost all functions used in blockchains today are public functions i.e. execution trace is transparently recorded onchain. The idea of a private function, mentioned first time in the ZEXE paper, allows the execution trace to be done locally on the user end (as opposed to a public function, which is executed by the validators or other non-user parties, transparently) so as it is privacy-preserving. What becomes quite interesting is that then the interaction between public function and private function enables private local state and public global state to exist at the same time (e.g using private balance to interact with public liquidity pool on uniswap). It also created a massive engineering challenge. We see teams like Aleo have made a trade-off to prioritize performance by disabling the private function for the time being. Aztec is by far the only protocol having the private function switch on. By contrast, FHE-based networks only have public functions, and the reason is that the FHE computation is delegated to validators due to computation extensiveness. Private function probably is not quite proper for a FHE network either. Finally, whether a function should be made public or private depends on what degree of privacy users would want and the specific use case. For example, when using private uniswap, retail probably would care more about hiding the size of their position, as opposed to which specific pool they are interacting with. But institutions/pro traders would care both to preserve complete privacy for their strategies. This post by Equilibrium shares lots of great insights into the technical trade-offs for different settings.
5_We yet don’t have a perfect private trading venue.
We discussed the intricacies of building a distributed privacy-preserving system, but implementing a private dapp is not easy either. DeFi is by far the most vibrant application ecosystem, yet most activities happen in a completely transparent manner See (as discussed in one of our previous research pieces)
There are mainly two designs for an onchain trading venue: AMM and order book. The private versions of them are private AMM and onchain darkpool, where traders can preserve the privacy of the trade’s attributes (i.e., trader identity, asset pair, order size, etc.).
- Private AMM
‘Transparent AMM’ like uniswap is widely used mainly because it really leverages the advantage of the blockchain – having a shared, global ledger, that anyone can track liquidity status and swap assets concurrently. When it comes to private AMM, maintaining (i.e. tracking and changing) a private global state is hard. Barry explained already a few years ago why it’s not ‘possible’ to use ZK in Ethereum kind of account models – ZK is used for proving user-specific (i.e. single person) state and there is no way to generate a ZKP to prove multiple users’ state (if so, privacy is compromised). In addition, front-running problems (basically a way to maliciously keep the sender’s state changing) can also make users’ transactions obsolete. Tarun also touches on this problem and suggested we can try adding diff. Privacy or using batch order to mitigate information leakage. ZEXE should be mentioned here as it pioneered with public and private states where the public state maintains the public info regarding the pools and the private state, in the form of UTXO, allows users to interact with the pool anonymously, bypassing the problem that purely account model based blockchain has. A DeFi adapter is also something similar here. The batching order solution mentioned earlier, adopted by Penumbra, sidesteps the concurrency problem and creates a shared private state among users, but also comes with their own trade-off such as a non-ideal trader experience. FHE-based AMM is more elegant as it natively allows shared private state and thus it can manage concurrency and privacy at the same time, while most of them suffer from performance issues. - Onchain darkpool
We also see explorations toward building an onchain darkpool – renegade, enclave, singularity. The core mechanism of a darkpool is matching, which does not need a synchronous global state update that AMM requires. MPC and FHE are the best-fit techs to solve the challenge. tFHE, which is the latest generation of the FHE scheme, leveraging its advantage in number comparison, is a great fit for financial use cases such as darkpool. But currently performance overhead is a big challenge. MPC also allows to fairly run a function over a set of distributed values that is unknown to other participants. Except collusiveness, another drawback is that participants of the MPC network are required to be online until a match is found. This obviously degrades trader experience and orders types such as limit orders cannot be automatically executed. Some use relayer (i.e. trader send orders to relayer) to help facilitate the matching process but it compromises the trader’s privacy, though funds are safe. In general, the adoption of onchain darkpool also sees some challenges, such as the bootstrapping problem (i.e. anonymity can be compromised if there is only a known set of participants), performance (i.e. if the protocol meets basic HFT latency requirements), trust assumption, etc… Plus, lots of design specifics is also TBD, such as the execution price, settlement (period vs continuous auction), most of which have been mentioned in this post. We also recommend taking a look at this post by Delphi for some of the darkpool details. There is also a very cool implementation in JP Morgan’s darkpool that is running today. It uses app-specific MPC, and only matches quantity.
#6 – #7: (Mis)using terms and wording
6_Jargons are used everywhere. Don’t take them too seriously before diving deeper.
Many protocols employ multiple cryptographic primitives simultaneously, making it logical to advertise this fact. For instance, ZK-based systems often use homomorphism to aggregate values, FHE also uses ZKP to prove users’ knowledge of plaintext to authenticate user’s integrity. Thus, claims like “we use ZK and homomorphic encryption (HE)” or “we use FHE and ZK” are accurate but can be also confusing because it’s not clear what’s the base technology and what technology is a support function. The specific implementation details of these technologies are rarely mentioned upfront and typically require an in-depth review of the documentation. Importantly, using more technologies doesn’t necessarily imply greater system complexity or more value per se (depending on the specific use case sometimes one tech can fulfill the purpose). Furthermore, even when using the same technology, the complexity can vary significantly; for instance, developing a zkEVM is vastly more challenging than creating a ZK dApp. In addition, protocols also start to advertise them as a private re-staking layer as some hype around staking is clearly picked up. It is misleading as naturally one would think of it as doing re-staking in a private manner, which is apparently not the case.
Privacy is also a widely discussed topic in MEV. There are two forms of privacy – private order flow in terms of the transactions not being publicly visible as in public mempool, and user privacy, in which the transaction details are not exposed to searchers. We should make it clear that privacy is preserved in the context of pre-execution, and post execution everything is public (in a public blockchain).
7_Privacy is contextual. Define who is the observer first.
We in web3 always refer to privacy without mentioning any context which makes ‘private to who’ sometimes confused. We should make it explicit that privacy is preserved to which parties. For instance, as mentioned above, in some darkpool designs, privacy is respected in a way that outsiders cannot view what’s happening in the protocol while the relayer still has access to certain information. In tornado cash’s case, when withdrawing, the relayer can potentially link one’s IP address and their wallet (this is what makes a private VPN provider like NYM is critical). Relayers cannot hold clients’ funds in custody but if they turn malicious, privacy is compromised.
Conclusion
Privacy and particularly confidential compute remain a complex challenge. In view of different and partly overlapping cryptographic approaches and technologies, users and even devs can easily get confused and miss some details. We hope that this article contributes to a more comprehensive dialog and will reduce friction and misalignment. This is very critical as we move on as a community to have shared vision and knowledge toward solving one of the most complex and crucial problems in blockchain. We make by no means any claim to completeness. But if future debaters are more attentive to what exactly they are talking about when they talk about confidential compute, then this piece will have served its purpose.
We will be attending lots of FHE/ZK/MPC/privacy events during Ethcc! Come and say ‘Hallo’! Also feel free to reach out to us on CT.